
Technology
What are The 5 Key Stages of Resilience Lifecycle Framework
What are The 5 Key Stages of Resilience Lifecycle Framework? The Resilience Lifecycle Framework is a structured, iterative model that helps organizations, systems, and individuals prepare for, respond to, recover from, and grow after disruptions. It’s not just about surviving failures—it’s about building capacity so that when disruptions occur, the damage is minimized, recovery is faster, and lessons learned feed back into future readiness.
AWS, Cordless.io, and other resilience thought-leaders define this framework in varying but overlapping ways. For example, AWS describes five key stages in their Resilience Lifecycle Framework: Set Objectives, Design & Implement, Evaluate & Test, Operate, and Respond & Learn.
Understanding this lifecycle matters because disruption is inevitable—whether from natural disasters, cyber-attacks, supply chain breakdowns, or personal crisis. Resilience frameworks provide a roadmap so disruptions are less damaging, responses are effective, and systems emerge stronger.
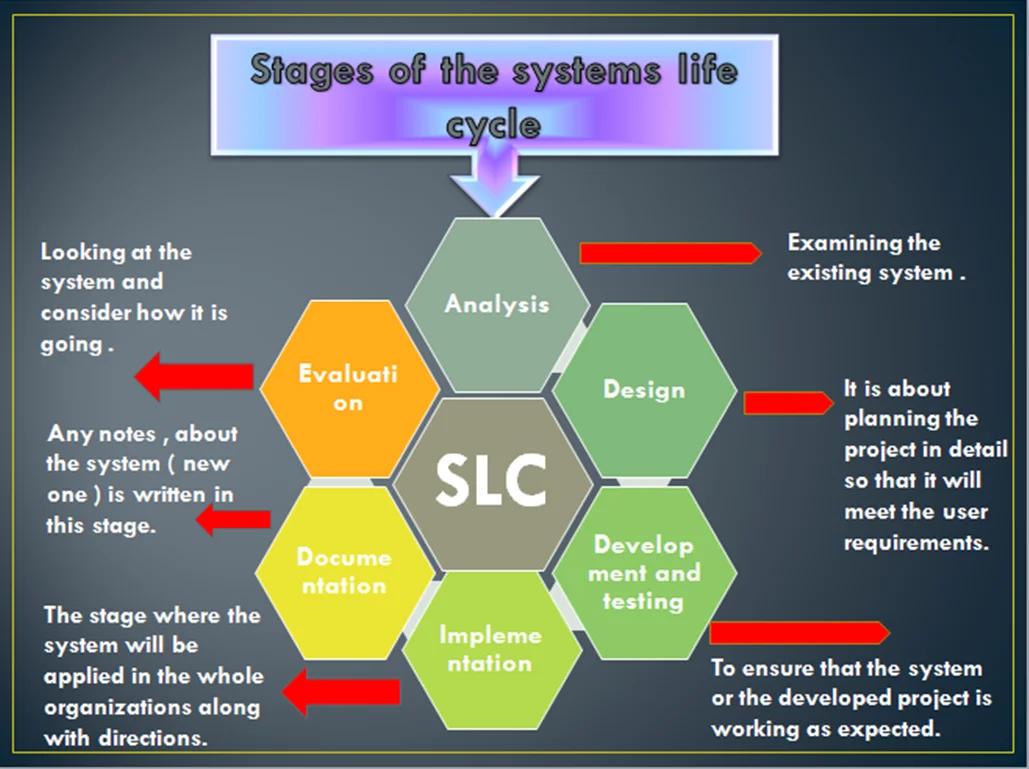
Stage 1: Set Objectives (Anticipate & Prepare)
The first stage is about anticipation—defining what resilience means in concrete terms, clarifying the threats, and preparing in advance.
Key Elements
- Risk Identification: mapping out internal and external risks, vulnerabilities, dependencies. What can go wrong? What has gone wrong in the past?
- Setting Metrics & Priorities: defining Recovery Time Objectives (RTOs), Recovery Point Objectives (RPOs), acceptable levels of downtime, acceptable data loss, etc. Which systems or functions are critical?
- Stakeholder Alignment & Communication: ensuring leadership, technical, and business units agree on what “enough resilience” looks like. Shared understanding is essential.
Why This Stage Is Critical
Without clear objectives, efforts in later stages may waste resources or fail to cover what matters most. If you don’t know which systems or outcomes are mission-critical, you might defend less important parts at the cost of vital ones. Also, anticipation and preparation reduce shock when disruptions hit. Hardened systems and plans reduce uncertainty and speed up response.
Stage 2: Design & Implement (Prevent & Build Resilience)
Once objectives are clear, the second stage is about putting in place the structures, processes, and defenses that embody resilience.
Key Actions
- Architectural design that avoids single points of failure: redundancy, fault tolerance, backup systems, geographic dispersion.
- Preventive controls & safeguards: for example, using strong cybersecurity protections, security policies, training, regular maintenance, health or operational checks.
- Operational playbooks / runbooks: documenting what to do in case of specific failures. Plans for failover, escalation, communication.
Implementation Challenges
- There are always trade-offs (cost, complexity, performance). More redundancy or backups means more cost and possible overhead. Finding the balance is important. AWS notes these trade-offs explicitly.
- Ensuring the implementation is not just theoretical: the safeguards must be properly deployed, tested, and maintained as systems evolve.
Stage 3: Evaluate & Test (Validate & Stress-Test)
After designing and implementing resilience mechanisms, these must be validated. This stage is about testing whether the systems behave as expected under stress or failure conditions.
What Happens Here
- Simulations, drills, scenario testing: introduce failures in controlled environments (e.g. a server crash, network failure, outage simulation, etc.) to check how systems respond.
- Chaos engineering or fault injection: deliberately triggering faults or disruptions to observe system behaviour and expose weaknesses.
- Monitoring & observability: gathering metrics, logs, tracing, alerting to detect failures or anomalies and measure system performance under load or failure conditions.
Why It Matters
Without evaluation and testing, resilience features may fail when you need them most. Tests reveal flaws, gaps, and assumptions that might not hold true in real events. This stage provides feedback to feed into improvements. The resilience lifecycle is cyclical: what we learn here helps improve Setting Objectives and the design/implementation in the next cycle.
Stage 4: Operate (Maintain & Monitor in Continuity)
This stage involves daily operation of resilient systems—keeping them running, maintaining situational awareness, and ensuring that resilience isn’t just theoretical but embedded.
Core Components
- Continuous monitoring: watching system health, performance, error rates, capacity usage, and early warning metrics.
- Drift detection & maintenance: systems tend to diverge from their design over time (configuration drift, vulnerabilities, patch lag). Regular audits, updates, and maintenance ensure defenses remain effective.
- Incident detection & alerting: being alert to anomalies early so you can respond before large-scale damage.
Embedding Resilience in Operations
Resilience should not be shelved until disaster hits. Operating with resilience means anticipating issues in daily work: ensuring backups are valid, disaster recovery plans are tested, support and roles are understood, teams can act when required. This keeps systems robust and builds institutional muscle.
Stage 5: Respond & Learn (React, Recover & Improve)
This final stage is about handling disruption when it happens, learning from the event, and evolving to better resilience in the next cycle.
Response: What Happens During a Disruption
- Quick activation of incident response: communication, containment, mobilization of resources, executing playbooks.
- Recovery efforts: restoring critical services, recovering data, repairing damage. Minimizing downtime and losses.
Learning & Adaptation
- Post-incident analysis or post-mortem: what caused the issue, what worked, what didn’t.
- Feeding back lessons: updating policies, improving design, refining monitoring or detection, adjusting objectives if needed.
- Culture of improvement: embedding continuous learning, avoiding blame, encouraging transparency and corrective action.
Why Respond & Learn Is the Keystone
Without this final stage, resilience risks being superficial. Systems may recover, but the same or similar failures may repeat. By combining response with reflection and adaptation, you close the loop—making future resilience stronger. The framework becomes not a one-time effort but a continuous process.
Bringing It All Together: The Lifecycle Nature & Practical Tips
A few observations and recommendations for applying the Resilience Lifecycle Framework well:
- Cyclical process: The five stages don’t happen once; after responding and learning, you loop back to setting objectives and preparing again because threats evolve. AWS explicitly frames it as a continuous improvement loop.
- Context matters: The details in each stage differ by domain—IT systems will focus on redundancy, failover, metrics; communities or personal resilience might emphasize social networks, emotional well-being, adaptive behaviors.
Practical Tips for Implementation
- Start small: Pilot the lifecycle framework in one business unit, or one system, rather than rolling out across everything at once.
- Define measurable goals: RTO, RPO, acceptable risk levels, performance under stress.
- Regular testing: schedule drills, chaos-engineering, or simulations periodically so you don’t assume everything works until a real incident.
- Ensure stakeholder buy-in: leadership, operations, security, business owners must understand and support resilience efforts (they’re often cross-cutting).
- Document & share learnings: create a knowledge base of incidents, responses, and improvements so the organization doesn’t forget.
Conclusion
The Resilience Lifecycle Framework (or Resilience Lifecycle) defines five key stages:
- Set Objectives (Anticipate & Prepare)
- Design & Implement (Prevent / Build Resilience)
- Evaluate & Test (Validate and Stress-Test)
- Operate (Maintain & Monitor)
- Respond & Learn (React, Recover, Evolve)
These stages help ensure that resilience is not reactive or ad hoc but proactive, embedded, measurable, and evolving. Organizations and individuals that follow these stages are better positioned to withstand shocks, recover more quickly, and emerge stronger.
Technology
How Container Tracking Platforms Help Logistics Teams Save Time, Reduce Delays, and Improve Supply Chain Visibility
Global supply chains have become increasingly complex over the past few years. Events such as disruptions in the Red Sea, geopolitical tensions affecting the Strait of Hormuz, port congestion, labor shortages, and shifting trade routes have made international transportation less predictable than ever before.
At the same time, customer expectations have changed. Businesses no longer accept waiting days for shipment updates, and customers expect accurate delivery information throughout the transportation process. Whether a company is importing raw materials, exporting finished products, or coordinating inventory across multiple countries, shipment visibility has become a critical operational requirement.
The challenge is that modern supply chains involve multiple stakeholders. A single shipment may pass through several ports, ocean carriers, terminals, customs authorities, warehouses, and trucking providers before reaching its destination. Monitoring every stage manually can quickly become overwhelming.
As a result, logistics teams increasingly rely on digital visibility platforms that provide real-time shipment information from multiple sources. These technologies help businesses track cargo movements, identify potential delays earlier, automate routine monitoring tasks, and improve decision-making across the supply chain.
What Is Container Tracking?
Container tracking is the process of monitoring the location and status of cargo as it moves through global transportation networks.
Traditionally, shipments were tracked using information provided directly by transportation companies. Today, modern tracking platforms allow users to monitor shipments using a container number, booking number, or bill of lading (a shipping document used to identify cargo).
Tracking information can cover every stage of transportation, including:
- Departure from origin ports
- Vessel movements across oceans
- Transshipment operations
- Terminal handling activities
- Customs clearance milestones
- Inland transportation updates
- Final delivery status
Modern tracking platforms provide far more than simple location data. Advanced systems typically include:
- Real-time shipment updates
- Estimated Time of Arrival (ETA) predictions
- Delay notifications
- Route visualization
- Historical shipment records
- Exception monitoring
- Performance analytics
In other words, container tracking has evolved from a basic tracking function into a source of operational intelligence that helps organizations make faster and more informed decisions.
The Challenges of Traditional Shipment Monitoring
Before adopting modern tracking platforms, many logistics teams rely on manual processes that consume significant amounts of time and create operational inefficiencies.
Manual Carrier Checks
One of the most common challenges involves checking shipment status across multiple carrier websites.
A logistics coordinator may need to:
- Open several carrier portals
- Enter container numbers individually
- Review shipment milestones
- Compare updates from different sources
- Copy information into internal systems
When managing dozens or hundreds of shipments simultaneously, these tasks become highly repetitive.
Spreadsheet-Based Tracking
Many organizations continue to manage shipments using spreadsheets.
While spreadsheets are flexible, they introduce several limitations:
- Manual data entry requirements
- Delayed status updates
- Version-control issues
- Increased risk of human error
- Difficulty collaborating across teams
As shipment volumes grow, spreadsheets become increasingly difficult to maintain.
Reactive Decision-Making
Perhaps the biggest challenge is that delays are often discovered too late.
Without automated monitoring, logistics teams may learn about disruptions only after customers begin asking questions or inventory shortages start affecting operations.
This reactive approach reduces the time available to:
- Adjust transportation plans
- Reschedule warehouse activities
- Notify customers
- Allocate alternative inventory
The result is higher operational risk and reduced supply chain agility.
How Modern Container Tracking Platforms Work
Modern visibility platforms solve these challenges by collecting and consolidating shipment information from multiple data sources into a single interface.
Data Sources
Today’s tracking systems aggregate information from:
- Ocean carriers
- Port community systems
- Terminal operators
- Vessel tracking networks
- Inland transportation providers
- Customs and logistics databases
Instead of requiring employees to check each source individually, the platform automatically gathers and organizes relevant shipment information.
Centralized Dashboard
The collected data is displayed through a centralized dashboard.
This allows logistics teams to view:
- Active shipments
- Current container status
- Estimated arrival dates
- Delay risks
- Historical shipment activity
Users gain a complete overview of transportation operations without switching between multiple systems.
Automated Updates
One of the most valuable capabilities is automated event monitoring.
The platform continuously monitors shipment activity and automatically refreshes information when new events occur.
Examples include:
- Vessel departure confirmations
- Port arrival notifications
- Terminal release events
- Customs clearance updates
- Route deviations
- Schedule changes
Many platforms also generate exception alerts when delays or disruptions are detected.
Advanced solutions recalculate ETAs dynamically as new information becomes available, providing more accurate arrival forecasts throughout the shipment journey.
Operational Benefits for Logistics Teams
Saving Time Through Automation
Time savings are often one of the first measurable benefits organizations experience.
Consider a logistics coordinator responsible for monitoring 500 active containers each month.
Using a manual process:
- Average status check: 3 minutes
- 500 containers × 3 minutes = 1,500 minutes
- Total monthly monitoring time: approximately 25 hours
With a modern tracking platform:
- Status collection becomes automated
- Alerts highlight only exceptions requiring attention
- Monitoring workload falls to approximately 3–5 hours monthly
This represents a reduction of up to 80% in routine tracking effort.
Those recovered hours can be redirected toward customer support, planning activities, and problem-solving tasks that generate greater business value.
Faster Response to Delays
Transportation disruptions are unavoidable.
Common examples include:
- Vessel schedule changes
- Port congestion
- Customs processing delays
- Transshipment disruptions
- Weather-related incidents
The difference lies in how quickly companies become aware of the problem.
If a five-day delay is detected immediately through automated alerts, logistics teams can:
- Adjust trucking schedules
- Reschedule warehouse labor
- Update inventory forecasts
- Inform customers proactively
Earlier awareness often reduces the operational impact of disruptions significantly.
Reducing Human Error
Manual processes inevitably introduce mistakes.
Common issues include:
- Incorrect container numbers
- Missed shipment updates
- Outdated spreadsheet records
- Duplicate entries
Automated synchronization reduces reliance on manual data entry and improves information consistency across teams.
Greater accuracy leads to better planning decisions and fewer operational surprises.
Improving Team Productivity
Many logistics professionals spend a large portion of their day collecting information rather than acting on it.
Tracking platforms automate repetitive monitoring activities, allowing employees to focus on:
- Exception management
- Customer communication
- Strategic planning
- Supplier coordination
- Transportation optimization
This shift from administrative work to decision-making work can significantly improve overall team productivity.
Real-World Optimization Examples
Example 1: Import Business
An importing company receives approximately 200 containers each month.
Before implementing a visibility platform:
- One employee spends roughly 15 hours weekly monitoring shipments
- Total monthly monitoring workload: approximately 60 hours
After implementation:
- Most shipment updates become automated
- Manual monitoring falls to around 10 hours monthly
Result:
- Approximately 50 hours saved each month
- Faster issue identification
- Greater focus on supplier coordination and inventory planning
Example 2: Freight Forwarder
Freight forwarders frequently receive requests from customers asking for shipment updates.
Without self-service visibility:
- Support teams answer dozens of status inquiries daily
- Significant time is spent gathering shipment information
After implementing a customer-accessible tracking portal:
- Customers can check shipment status independently
- Notifications are generated automatically
Potential outcome:
- Up to 70% fewer shipment status emails and calls
- Reduced support workload
- Faster customer response times
- Improved client satisfaction
Example 3: Retail Supply Chain
A retailer relies on imported inventory to maintain stock availability.
Previously:
- Shipment delays were discovered late
- Warehouse schedules required frequent adjustments
- Stock shortages occurred unexpectedly
After introducing real-time ETA monitoring:
- Delay alerts arrive earlier
- Inventory planning becomes more accurate
- Warehouse operations can prepare proactively
Result:
- Improved inventory availability
- Reduced operational disruptions
- Greater predictability across the supply chain
Key Performance Metrics Improved by Tracking Platforms
| Metric | Traditional Process | With Tracking Platform |
| Time spent monitoring shipments | 20–60 hours/month | 3–10 hours/month |
| Delay detection speed | Hours or days | Near real time |
| ETA accuracy | Moderate | Significantly improved |
| Shipment visibility | Fragmented | Centralized |
| Manual data entry | High | Minimal |
| Customer inquiry volume | High | Reduced significantly |
| Response time to disruptions | Reactive | Proactive |
| Operational efficiency | Limited by manual processes | Improved through automation |
While actual results vary between organizations, the overall trend is consistent: greater visibility leads to faster decisions and more efficient operations.
Beyond Tracking: Additional Features of Modern Visibility Platforms
Container tracking platforms have evolved considerably beyond basic shipment monitoring.
Many modern solutions now provide a broader set of supply chain intelligence capabilities, including:
Route Visualization
Interactive maps help teams understand where shipments are located and how cargo is moving through transportation networks.
Historical Shipment Analytics
Organizations can analyze past shipment performance to identify recurring delays and improve planning decisions.
Carrier Performance Monitoring
Performance metrics help businesses compare transportation providers based on reliability, transit times, and schedule consistency.
Automated Notifications
Users receive alerts when important events occur, reducing the need for manual monitoring.
Multiple Shipment Tracking
Large shipment volumes can be monitored simultaneously through centralized dashboards.
API Integrations
Many platforms connect directly with ERP, CRM, transportation management, and inventory systems, creating a more unified operational environment.
Reporting Dashboards
Executives and operations teams can monitor key logistics performance indicators through visual reporting tools.
Solutions such as TimeToCargo illustrate this evolution by combining container tracking with route visualization, time-based notifications, shipment dashboards, multiple-container monitoring, and API integrations that support broader supply chain workflows.
The industry is clearly moving from simple tracking tools toward comprehensive visibility and intelligence platforms.
Which Businesses Benefit Most?
Importers
Importers depend on predictable arrival schedules to manage inventory levels and maintain business continuity.
Exporters
Exporters require visibility across international transportation routes to coordinate customer deliveries and production planning.
Freight Forwarders
Freight forwarding companies manage large shipment volumes and benefit from centralized monitoring and customer visibility tools.
Manufacturers
Manufacturers often rely on just-in-time supply chains and need accurate arrival forecasts for critical materials.
Retailers
Retail businesses depend on reliable inventory replenishment and benefit from earlier detection of transportation disruptions.
Conclusion
Container tracking is no longer simply a tool for locating cargo.
Modern visibility platforms have become essential operational technologies that help businesses automate routine processes, reduce manual workload, improve decision-making, and respond faster to supply chain disruptions.
By centralizing shipment information, providing real-time updates, and automating exception monitoring, these systems allow logistics teams to save dozens of working hours every month while improving service quality and operational efficiency.
The ability to identify delays earlier, improve ETA accuracy, and reduce customer inquiry volumes creates measurable business value across a wide range of industries.
As global supply chains continue to face uncertainty and increasing complexity, real-time visibility is rapidly becoming a competitive advantage rather than an optional capability.
Organizations that invest in digital logistics technologies today are likely to be better positioned to manage disruptions, improve customer experience, and build more resilient supply chains in the years ahead.
If you’re thinking about domestic or commercial solar panel installation, you should also consider battery storage. Solar battery storage allows you to store electricity generated by your solar panels so you can use it when you need it. Without a battery, any unused energy your system produces is usually sent back to the grid. With battery storage, you keep more of that energy on-site, making your system more efficient and giving you greater control over how and when you use electricity.
How energy is generated and stored
Solar panels generate electricity during daylight hours, with the highest output typically occurring around midday. This energy is produced as direct current (DC) electricity. An inverter then converts it into alternating current (AC), which can be used in your home or business.
If your system generates more electricity than you are using at that moment, the excess energy can be directed into a battery instead of being exported to the grid. The battery stores this electricity so it can be used later, such as in the evening or during periods of low sunlight.
Using stored energy
When your solar panels are not producing enough electricity to meet your needs, the system can draw energy from the battery. This usually happens automatically, without any action required from you. For example, after sunset, your stored energy can power lighting, appliances, or equipment.
If the battery becomes fully discharged, your system will then take electricity from the grid as normal. This ensures that you always have access to power when you need it.
How the system is managed
Solar battery systems are typically managed by a control system that decides when to store energy and when to use it. This process is automated to maximise efficiency. The system will usually prioritise using solar energy first, then stored energy, and finally grid electricity if needed.
Many systems include monitoring tools that allow you to track how much energy you generate, store, and use. This can give you a clearer understanding of your energy habits and help you make more informed decisions about usage.
Charging the battery
The battery is charged using excess solar energy generated during the day. In some cases, it can also be charged using electricity from the grid, for example during off-peak hours when energy is cheaper. This depends on how your system is set up and your specific requirements.
Charging is carefully managed to protect the battery and ensure long-term performance. Modern batteries are designed to handle regular charging and discharging cycles over many years.
Discharging the battery
When energy is needed, the battery releases stored electricity back into your system. This process is known as discharging. It allows you to use your own stored energy instead of purchasing electricity from the grid.
The system will control how quickly the battery discharges based on your energy demand and the available charge. This helps maintain a balance between meeting your needs and preserving the battery’s lifespan.
Improving energy efficiency
By storing excess solar energy, battery systems help you use more of the electricity your panels generate. This reduces the amount of energy you need to import from the grid and can lead to lower energy costs over time.
It also means less energy is exported, which can be beneficial if export rates are lower than the cost of buying electricity. Overall, this improves the efficiency and value of your solar system.
Providing backup power
Some solar battery systems can provide backup power during a power cut. If configured to do so, the battery can supply electricity to selected circuits when the grid is unavailable. This can help maintain essential functions, such as lighting or critical equipment.
Not all systems include this feature, so it is important to consider this when choosing a battery.
Maintenance and lifespan
Solar batteries are designed to be low maintenance. They generally require minimal attention beyond occasional checks to ensure they are operating correctly. Most modern batteries have a lifespan of 10 to 15 years, depending on usage and the type of battery.
Over time, the battery’s storage capacity may gradually decrease, but it will continue to provide value throughout its lifespan.
Conclusion
Solar battery storage works by capturing excess energy generated by your solar panels and making it available for use at a later time. It operates automatically to store and release energy as needed, helping you make better use of renewable power. By adding a battery to your system, you can improve efficiency, reduce reliance on the grid, and gain greater control over your energy use.

The machine shop at 2 AM has a particular sound. It’s not the roar of the daytime, when people are yelling over spindles and forklifts beep their warnings. It’s a hum. A drone of machines at work, slow and steady, nearly meditative, and as they have nothing to watch over, their doors shut, and their lights throwing long blue rectangles on the concrete floor.
I am in the presence of Marcus who is the supervisor of night shift. He has twenty-two years of CNC machine running. A fine gray grime permanently stains his hands, which cannot be removed by soap.
I listen. I hear the machine.
“No,” I admit.
He nods, still listening. “It’s nervous.”
You push it, it’ll chatter. Leave a bad finish. The part passes inspection, maybe, but it’s stressed. It’ll move later, during assembly. The customer won’t know why it doesn’t fit. They’ll blame their design. But it’s not their design. It’s us. It’s me not listening.”
But the machine’s sound shifts, just slightly. The whine evens out. “There,” he says. “Happy now.”
The Silence of the Day Shift
During the day, the shop is a different world. Salespeople are on the phone. Engineers are reviewing files. Project managers are updating spreadsheets. Everyone is busy, moving, talking.
But in the quiet moments, when a day shift machinist finishes a setup and hits the green button, they do the same thing Marcus does. They listen. They watch the chips curl off the tool. They run a finger along the first part, not measuring, just feeling. This is the ritual. It’s not in the quality manual.
The One That Got Away
Every machinist has a story about the one that got away. The part they shipped that came back. Marcus has his.
“Five years ago,” he says, still staring at the now-happy machine. “Medical component. Titanium. I was rushing. We had a deadline, the customer was breathing down my neck. I skipped a finish pass. The part measured fine.
He pauses. The machine hums.
“Six months later, I get a call. The part failed in surgery. Not catastrophic, thank God. But it didn’t perform. The surgeon had to switch to a backup. The patient was under longer than necessary. All because I rushed. All because I didn’t listen.”
He looks at me. Why are you asking me why I am here at 2 AM? Why I am the one who listens to nervous machines? He says because I am the guy who did not hear that day. And I will have to pay my life long to recoup it.
What You’re Actually Paying For
When you send a RFQ to a shop, you’re not just paying for machine time and material. You’re paying for Marcus’s guilt. You’re paying for the night shift rituals. You’re paying for the decades of mistakes that taught someone to hear the difference between a happy machine and a nervous one.
You’re paying for the institutional memory of a thousand tiny failures that never happened to your part because they happened to someone else’s, years ago, and the lesson was absorbed into the fingertips of every machinist in the building.
This is the invisible line item on every invoice. It’s never listed. It’s never discussed. But it’s the most important thing you’re buying.
The Part That Arrives
When your box comes at last, when you reach out and draw out that perfect, shining part, when you feel the edge of your thumb, when you find it sliding across, and you find out that it is not hard at all, but smooth, and solid, and sure, you will be too blind to know about Marcus. You will never hear of the 2 am changes or the guilt or the listening.
You will simply know that it is right. Solid. Quiet.
That silence is the voice of a promise made. It is the voice of a person devoted enough to listen or pay attention when nobody is around. It’s the sound of CNC machining services that understand the difference between making a part and honoring a trust.
The machine made the chips. But Marcus made the part.


Is Hizzaboloufazic Good or Bad? Full 2025–2026 Analysis & Safety Review

Sustore: What “Sustore” Means Across E-Commerce, Retail, and IT



